Cloudflare فایروال ویژه هوش مصنوعی معرفی کرد
Cloudflare امروز از توسعه یک لایه حفاظتی به نام Firewall for AI برای محافظت از مدلهای زبان بزرگ (LLMs) خبر داد.

به گزارش خبرگزاری مهر، در حالی که استفاده از مدلهای هوش مصنوعی، بهویژه مدلهای زبان بزرگ، به سرعت در حال گسترش است، بسیاری از مشتریان ابراز کردهاند که به دنبال بهترین راهکارها برای حفاظت از LLMهای خود هستند. استفاده از LLMها در برنامههای کاربردی مبتنی بر اینترنت باعث به وجود آمدن آسیبپذیریهای جدیدی شده که ممکن است توسط مهاجمان مخرب مورد سوءاستفاده قرار گیرد.
برخی از آسیبپذیریهایی که در برنامههای سنتی وب و API وجود دارند، در دنیای LLMها نیز مشاهده میشوند، از جمله حملات تزریق (Injection) یا استخراج غیرمجاز دادهها (Data Exfiltration). اما در عین حال، نوع جدیدی از تهدیدات نیز به دلیل نحوه عملکرد LLMها پدید آمده است. برای مثال، اخیراً محققان یک آسیبپذیری در یک پلتفرم همکاری مبتنی بر هوش مصنوعی شناسایی کردند که به آنها امکان میداد کنترل مدلها را به دست گرفته و اقدامات غیرمجاز انجام دهند.
Firewall for AI یک فایروال پیشرفته برای برنامههای وب (WAF) است که بهطور خاص برای برنامههایی طراحی شده است که از LLMها استفاده میکنند. این محصول مجموعهای از ابزارها را در اختیار کاربران قرار میدهد که پیش از رسیدن به برنامهها مورد استفاده قرار میگیرند تا آسیبپذیریها شناسایی شوند و به صاحبان برنامهها دید شفافتری از وضعیت امنیتی خود ارائه شود.
این ابزار شامل قابلیتهایی است که قبلاً در WAF وجود داشتهاند، مانند محدودسازی نرخ درخواستها (Rate Limiting) و شناسایی دادههای حساس (Sensitive Data Detection). همچنین یک لایه محافظتی جدید نیز در حال توسعه است که بهطور خاص برای LLMها طراحی شده است. این لایه حفاظتی جدید، درخواستهای کاربر (Prompts) را تحلیل میکند تا تلاشهای سوءاستفاده، از جمله استخراج دادهها یا سایر روشهای سوءاستفاده از مدلها را شناسایی کند.
با استفاده از گستردگی شبکه Cloudflare، در دنیا از سرور های مجازی خارجی گرفته تا انواع هاستیگ ها این فایروال تا حد ممکن به کاربر نهایی نزدیک خواهد بود. این ویژگی باعث میشود حملات به سرعت شناسایی شوند و هم کاربران نهایی و هم مدلها در برابر سوءاستفاده و حملات محافظت شوند.
پیش از بررسی نحوه عملکرد و قابلیتهای کامل Firewall for AI، ابتدا لازم است درک کنیم که چه ویژگیهایی LLMها را منحصربهفرد میکند و چه نقاط ضعفی در این مدلها وجود دارد. در این راستا، از لیست OWASP Top 10 برای LLMها به عنوان مرجع استفاده خواهیم کرد.
چرا مدلهای زبان بزرگ (LLMs) با برنامههای کاربردی سنتی تفاوت دارند؟
اگر مدلهای زبان بزرگ (LLMs) را بهعنوان برنامههای کاربردی مبتنی بر اینترنت در نظر بگیریم، دو تفاوت اساسی با برنامههای وب سنتی وجود دارد.
اولین تفاوت در نحوه تعامل کاربران با محصول است. برنامههای سنتی ذاتاً دارای ویژگیهای قطعی (deterministic) هستند. به عنوان مثال، یک برنامه بانکی را در نظر بگیرید که از مجموعهای از عملیات مشخص پیروی میکند (مانند بررسی موجودی حساب، انجام تراکنش و غیره). امنیت عملیات تجاری (و دادهها) از طریق کنترل عملیات قابلپذیرش در این نقاط پایانی حاصل میشود: بهعنوانمثال، «GET /balance» یا «POST /transfer».
در مقابل، عملیات LLMها بهطور ذاتی غیرقطعی هستند. اولین تفاوت این است که تعاملات LLMها بر مبنای زبان طبیعی است، که شناسایی درخواستهای مشکلساز را دشوارتر از تطبیق امضای حمله (attack signatures) میکند. علاوه بر این، مدلهای زبان بزرگ بهطور معمول در پاسخهای خود متغیر هستند، مگر اینکه پاسخها کش (cache) شوند. به عبارت دیگر، حتی اگر همان ورودی (prompt) چندین بار تکرار شود، مدل ممکن است پاسخ متفاوتی ارائه دهد. این ویژگی، محدود کردن نحوه تعامل کاربر با برنامه را بسیار دشوار میکند. همچنین این موضوع میتواند خطراتی برای کاربران ایجاد کند، زیرا آنها ممکن است با اطلاعات نادرست مواجه شوند که میتواند اعتمادشان به مدل را کاهش دهد.
دومین تفاوت بزرگ در نحوه تعامل سطح کنترل برنامه با دادهها است. در برنامههای سنتی، سطح کنترل (کد) بهطور واضح از سطح دادهها (پایگاه داده) جدا است. عملیات تعریفشده تنها راه تعامل با دادههای زیرساختی هستند (برای مثال، «تاریخچه تراکنشهای من را نشان بده»). این جداسازی به کارشناسان امنیتی این امکان را میدهد که بر روی تجهیز سطح کنترل به کنترلها و محدودیتها تمرکز کنند و به این ترتیب، دادههای پایگاه داده بهطور غیرمستقیم محافظت شوند.
در LLMها اینگونه نیست. در این مدلها، دادههای آموزشی به بخشی از خود مدل تبدیل میشوند. این ویژگی باعث میشود کنترل نحوه انتقال این دادهها بهعنوان نتیجهای از ورودیهای کاربران بهمراتب پیچیدهتر شود. در حال حاضر، برخی از راهکارها در سطح معماری برای حل این مشکل در حال تحقیق هستند، مانند تقسیم LLMها به لایههای مختلف و جداسازی دادهها. با این حال، هنوز هیچ راهحل قطعی پیدا نشده است.
از منظر امنیتی، این تفاوتها به مهاجمان این امکان را میدهند که بردارهای حمله جدیدی را طراحی کنند که LLMها را هدف قرار داده و ممکن است توسط ابزارهای امنیتی موجود که برای برنامههای وب سنتی طراحی شدهاند، شناسایی نشوند.
آسیبپذیریهای LLM از دیدگاه OWASP
بنیاد OWASP فهرستی از ۱۰ کلاس اصلی آسیبپذیری برای مدلهای زبان بزرگ (LLMs) منتشر کرده است که چارچوب مفیدی برای بررسی نحوه تأمین امنیت این مدلها ارائه میدهد. برخی از تهدیدات مشابه تهدیدات موجود در فهرست OWASP Top 10 برای برنامههای وب هستند، در حالی که برخی دیگر مختص به مدلهای زبان میباشند.
مشابه با برنامههای وب، برخی از این آسیبپذیریها بهترین حالت رفعشدنشان زمانی است که LLMها طراحی، توسعه و آموزش داده میشوند. برای مثال، «آلودهسازی دادههای آموزشی» (Training Data Poisoning) میتواند از طریق وارد کردن آسیبپذیریها به مجموعه دادههای آموزشی که برای آموزش مدلهای جدید استفاده میشود، انجام گیرد. این اطلاعات آلوده سپس به کاربر نمایش داده میشود زمانی که مدل در حال استفاده است. آسیبپذیریها در زنجیره تأمین نرمافزار و طراحی ناامن افزونهها نیز آسیبپذیریهایی هستند که به اجزای اضافهشده به مدل مربوط میشوند، مانند بستههای نرمافزاری از سوی اشخاص ثالث. در نهایت، مدیریت مجوزها و دسترسیها در مورد «اعتماد بیش از حد» (Excessive Agency) اهمیت دارد؛ یعنی مدلهایی که بدون محدودیت قادر به انجام اقدامات غیرمجاز در سراسر برنامه یا زیرساخت هستند.
در مقابل، تهدیداتی مانند «تزریق درخواست» (Prompt Injection)، «هجوم مدل به سرویس» (Model Denial of Service) و «افشای اطلاعات حساس» (Sensitive Information Disclosure) میتوانند با استفاده از راهحلهای امنیتی پروکسی مانند Cloudflare Firewall for AI دفع شوند. در بخشهای بعدی، بهطور دقیقتر به این آسیبپذیریها خواهیم پرداخت و توضیح خواهیم داد که چگونه Cloudflare بهطور مؤثر آماده مقابله با آنها است.
پیادهسازیهای LLM
ریسکهای مدل زبان همچنین به نوع پیادهسازی آن بستگی دارد. در حال حاضر، سه رویکرد اصلی برای پیادهسازی وجود دارد: LLMهای داخلی، عمومی و محصول. در هر سه حالت، شما باید مدلها را از سوءاستفاده محافظت کنید، دادههای مالکانهای که در مدل ذخیره میشوند را ایمن نگه دارید و از کاربران در برابر اطلاعات غلط یا محتوای نامناسب محافظت کنید.
– LLMهای داخلی: شرکتها مدلهای زبان بزرگ را برای پشتیبانی از کارمندان خود در انجام وظایف روزمره توسعه میدهند. این مدلها بهعنوان داراییهای شرکت در نظر گرفته میشوند و نباید برای افراد غیرکارمند قابل دسترس باشند. بهعنوان مثال، یک دستیار هوش مصنوعی که بر روی دادههای فروش و تعاملات مشتریان آموزش دیده است تا پیشنهادات سفارشیسازی شده ایجاد کند، یا یک مدل LLM که بر روی پایگاه داده دانش داخلی آموزش دیده است و میتواند توسط مهندسان مورد استفاده قرار گیرد.
– LLMهای عمومی: این مدلها LLMهایی هستند که میتوانند خارج از محدوده یک شرکت استفاده شوند. این راهحلها معمولاً نسخههای رایگان دارند که هر کسی میتواند از آنها استفاده کند و معمولاً بر روی اطلاعات عمومی یا دانش عمومی آموزش دیدهاند. از نمونههای این مدلها میتوان به GPT از OpenAI یا Claude از Anthropic اشاره کرد.
– LLMهای محصول: از دیدگاه یک شرکت، LLMها میتوانند جزئی از یک محصول یا خدمت باشند که به مشتریان ارائه میشود. این مدلها معمولاً راهحلهای سفارشیشدهای هستند که بهعنوان ابزاری برای تعامل با منابع شرکت در اختیار قرار میگیرند. نمونههایی از این مدلها شامل چتباتهای پشتیبانی مشتری یا دستیار هوش مصنوعی Cloudflare است.
از منظر ریسک، تفاوت بین LLMهای محصول و عمومی در این است که چه کسانی از تأثیرات حملات موفق آسیب میبینند. LLMهای عمومی بهعنوان تهدیدی برای حفظ حریم خصوصی در نظر گرفته میشوند، چرا که دادههای وارد شده به مدل میتوانند توسط هر کسی مشاهده شوند. این یکی از دلایلی است که بسیاری از شرکتها به کارکنان خود توصیه میکنند که از وارد کردن اطلاعات حساس در درخواستهای مدلهای عمومی خودداری کنند. از سوی دیگر، LLMهای محصول میتوانند تهدیدی برای شرکتها و داراییهای فکری آنها باشند، بهویژه زمانی که مدلها در طول آموزش (اعم از عمدی یا تصادفی) به اطلاعات محافظتشده دسترسی داشتهاند.
Firewall for AI
Cloudflare Firewall for AI مشابه یک فایروال وب معمولی (WAF) عمل میکند، جایی که هر درخواست API همراه با یک پرامپت LLM برای شناسایی الگوها و امضاهای حملات احتمالی اسکن میشود.
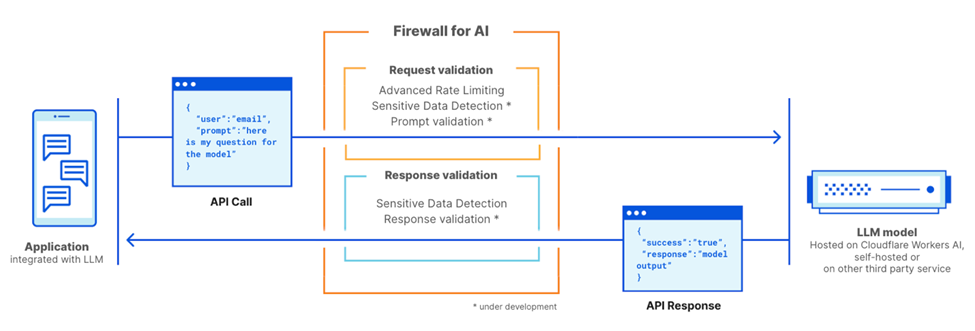
Firewall for AI میتواند قبل از مدلهایی که در پلتفرم Cloudflare Workers AI میزبانی میشوند یا مدلهایی که در زیرساختهای شخص ثالث میزبانی میشوند، مورد استفاده قرار گیرد. همچنین میتوان از آن همراه با Cloudflare AI Gateway استفاده کرد. مشتریان میتوانند Firewall for AI را از طریق لایه کنترل WAF مدیریت و تنظیم کنند.
Firewall for AI مانند یک فایروال وب Application معمولی عمل میکند. این ابزار قبل از یک برنامه LLM قرار میگیرد و هر درخواست را اسکن میکند تا امضاهای حمله را شناسایی کند.
جلوگیری از حملات حجمی
یکی از راه های جلوگیری از حملات CDN (شبکه تحویل محتوا) است. یکی از تهدیداتی که توسط OWASP ذکر شده، حمله مدل Denial of Service (DoS) است. مشابه برنامههای معمولی، در یک حمله DoS، با استفاده از حجم بالای درخواستها، منابع زیادی مصرف میشود که منجر به کاهش کیفیت سرویس یا افزایش هزینههای عملیاتی مدل میشود. با توجه به منابع وسیعی که LLMها برای اجرای خود نیاز دارند و غیرقابل پیشبینی بودن ورودیهای کاربران، این نوع حمله میتواند آسیبزا باشد.
این خطر با معرفی سیاستهای محدودیت نرخ (Rate Limiting) قابل دفع است که نرخ درخواستها از هر نشست را کنترل کرده و بدین ترتیب، پنجرههای متنی را محدود میکند. اگر مدل خود را از طریق Cloudflare بهعنوان یک پراکسی استفاده کنید، بهطور فوری از محافظت مؤثر در برابر حملات DDoS برخوردار خواهید شد. همچنین میتوانید از Rate Limiting و Advanced Rate Limiting برای مدیریت نرخ درخواستهایی که به مدل شما میرسند استفاده کنید و یک سقف برای تعداد درخواستهایی که از یک آدرس IP یا یک کلید API میتواند در یک نشست انجام دهد، تعیین کنید. در این شرایط باید کارشناسان سرور و هاستینگ در ارتباط باشید.
شناسایی اطلاعات حساس با استفاده از Sensitive Data Detection
دو سناریو برای دادههای حساس وجود دارد، بسته به اینکه آیا شما مالک مدل و دادهها هستید یا اینکه میخواهید از ارسال دادهها به مدلهای عمومی LLM جلوگیری کنید.
همانطور که OWASP تعریف کرده است، افشای اطلاعات حساس زمانی رخ میدهد که مدلهای LLM بهطور تصادفی اطلاعات محرمانه را در پاسخهای خود فاش کنند، که منجر به دسترسی غیرمجاز به دادهها، نقض حریم خصوصی و تخلفات امنیتی میشود. یک روش برای جلوگیری از این اتفاق اضافه کردن اعتبارسنجیهای دقیق درخواستها است. رویکرد دیگر، شناسایی زمانی است که دادههای شخصی (PII) از مدل خارج میشود. این بهویژه زمانی اهمیت دارد که مدل بر اساس یک پایگاه داده دانش داخلی آموزش داده شده باشد که ممکن است حاوی اطلاعات حساس مانند دادههای شخصی (برای مثال شماره تأمین اجتماعی)، کدهای محافظتشده یا الگوریتمها باشد.
مشتریانی که مدلهای LLM را پشت Cloudflare WAF استفاده میکنند، میتوانند از مجموعه قوانین WAF به نام Sensitive Data Detection (SDD) برای شناسایی PII خاصی که توسط مدل در پاسخ باز میگردد، استفاده کنند. مشتریان میتوانند نتایج حساس SDD را در رویدادهای امنیتی WAF بررسی کنند. در حال حاضر، SDD بهعنوان مجموعهای از قوانین مدیریتشده ارائه میشود که برای جستجو در دادههای مالی (مانند شماره کارت اعتباری) و اسرار (کلیدهای API) طراحی شده است. در نقشه راه آینده، ما قصد داریم به مشتریان این امکان را بدهیم که امضاهای خود را بسازند.
سناریوی دیگری که وجود دارد این است که از ارسال دادههای حساس (مانند PII) توسط کاربران به مدلهای عمومی LLM مانند OpenAI یا Anthropic جلوگیری کنیم. برای محافظت از این سناریو، ما قصد داریم SDD را گسترش دهیم تا بتوانیم پرامپت ورودی و خروجی آن را در AI Gateway اسکن کنیم، جایی که میتوانیم همراه با تاریخچه پرامپت، شناسایی کنیم که آیا دادههای حساس خاصی در درخواست وجود دارند یا خیر. ابتدا از قوانین موجود SDD استفاده خواهیم کرد و سپس قصد داریم به مشتریان این امکان را بدهیم که امضاهای سفارشی خود را بنویسند. در این راستا، مخفیسازی دادهها یک ویژگی دیگر است که بسیاری از مشتریان در مورد آن صحبت کردهاند. هنگامی که SDD پیشرفته در دسترس قرار گیرد، مشتریان میتوانند دادههای حساس خاصی را در یک پرامپت مخفی کنند قبل از اینکه به مدل برسد. SDD برای مرحله درخواست در حال توسعه است.
جلوگیری از سوءاستفاده از مدلها
سوءاستفاده از مدلها یک دسته وسیعتر از انواع سوءاستفادهها است. این شامل روشهایی مانند “تزریق پرامپت” یا ارسال درخواستهایی است که هالوسینیشنها (توهمات) ایجاد میکنند یا به پاسخهایی منجر میشوند که نادرست، توهینآمیز، نامناسب یا حتی بیربط به موضوع هستند.
تزریق پرامپت (Prompt Injection) تلاشی است برای دستکاری یک مدل زبانی از طریق ورودیهای بهویژه طراحیشده، بهطوری که واکنشهای غیرقابل پیشبینی از LLM ایجاد شود. نتایج این تزریق میتواند متفاوت باشد، از استخراج اطلاعات حساس گرفته تا تأثیرگذاری بر فرآیند تصمیمگیری از طریق شبیهسازی تعاملات طبیعی با مدل. یک مثال کلاسیک از تزریق پرامپت، دستکاری یک رزومه است که باعث میشود ابزارهای بررسی رزومهها تحت تأثیر قرار بگیرند.
یک کاربرد رایج که از مشتریان ما در Cloudflare AI Gateway دریافت میکنیم این است که آنها میخواهند از تولید زبان سمی، توهینآمیز یا آزاردهنده توسط برنامههای خود جلوگیری کنند. خطراتی که زمانی که نتایج مدل کنترل نشوند ایجاد میشود، شامل آسیب به شهرت و آسیب به کاربران از طریق پاسخهای غیرقابل اعتماد است.
این نوع سوءاستفاده میتواند با اضافه کردن یک لایه محافظتی اضافی قبل از مدل جلوگیری شود. این لایه میتواند طوری آموزش دیده باشد که تلاشهای تزریق یا پرامپتهایی که در دستههای نامناسب قرار میگیرند را مسدود کند.
اعتبارسنجی پرامپت و پاسخها
Firewall for AI مجموعهای از شناساییها را انجام میدهد که هدف آنها شناسایی تلاشهای تزریق پرامپت و دیگر تلاشهای سوءاستفاده است، مانند اطمینان از اینکه موضوع درخواستها در محدودیتهای تعیینشده توسط مالک مدل باقی بماند. مشابه سایر ویژگیهای موجود در WAF، Firewall for AI بهطور خودکار به جستجوی پرامپتهای جاسازیشده در درخواستهای HTTP پرداخته یا به مشتریان این امکان را میدهد که قوانینی بر اساس جایی که پرامپت در بدنه JSON درخواست یافت میشود، ایجاد کنند.
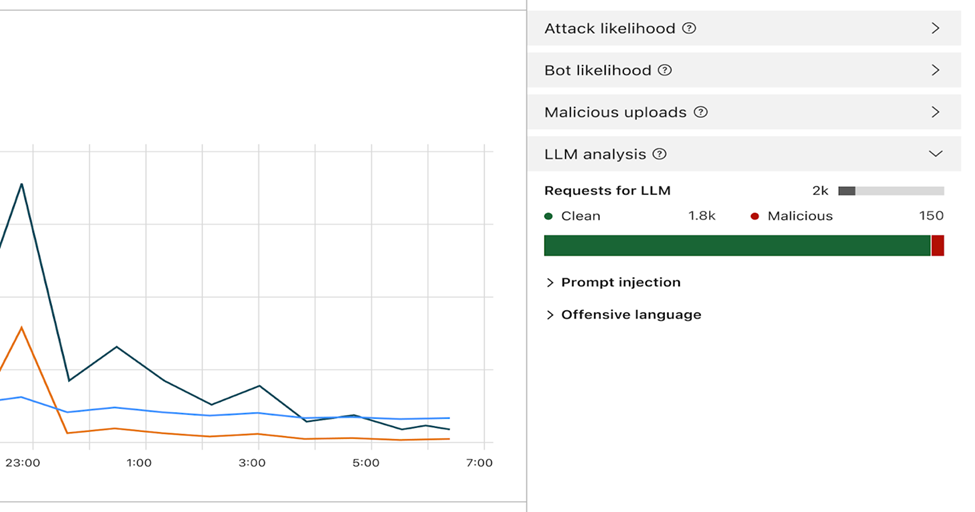
هنگامی که این ویژگی فعال شود، فایروال هر پرامپت را تجزیه و تحلیل کرده و امتیازی از احتمال بدخیمی آن ارائه میدهد. علاوه بر این، پرامپتها بر اساس دستهبندیهای از پیش تعریفشده علامتگذاری میشوند. امتیاز از ۱ تا ۹۹ متغیر است و احتمال وقوع تزریق پرامپت را نشان میدهد، بهطوری که ۱ بالاترین احتمال را دارد.
مشتریان قادر خواهند بود قوانینی در WAF ایجاد کنند تا درخواستهایی را که امتیاز خاصی در یکی یا هر دو بعد دارند، مسدود یا ویرایش کنند. آنها میتوانند این امتیاز را با دیگر سیگنالهای موجود (مانند امتیاز ربات یا امتیاز حمله) ترکیب کنند تا تصمیم بگیرند آیا درخواست باید به مدل برسد یا مسدود شود. بهعنوان مثال، این امتیاز میتواند با امتیاز ربات ترکیب شود تا شناسایی کند که آیا درخواست از یک منبع خودکار و بدخواه است.
شناسایی تزریقهای پرامپت و سوءاستفاده از پرامپتها بخشی از قابلیتهای Firewall for AI است. این ویژگی در حال توسعه است و در مراحل اولیه طراحی محصول قرار دارد.
علاوه بر ارزیابی، ما به هر پرامپت برچسبهایی اختصاص خواهیم داد که میتوانند در ایجاد قوانین برای جلوگیری از رسیدن پرامپتهای خاص به مدل استفاده شوند. بهعنوان مثال، مشتریان میتوانند قوانینی برای مسدود کردن موضوعات خاص ایجاد کنند. این شامل پرامپتهایی است که حاوی کلماتی هستند که بهعنوان توهینآمیز شناخته میشوند یا بهطور مثال با مذهب، محتوای جنسی یا سیاست مرتبط هستند.
چگونه از Firewall for AI استفاده کنم؟ چه کسانی به این ابزار دسترسی دارند؟
مشتریان سازمانی با پیشنهاد Application Security Advanced میتوانند فوراً با استفاده از Advanced Rate Limiting و Sensitive Data Detection (در مرحله پاسخ) شروع کنند. این دو محصول در بخش WAF داشبورد Cloudflare موجود است. ویژگی اعتبارسنجی پرامپت در Firewall for AI در حال حاضر در حال توسعه است و نسخه بتا در ماههای آینده برای تمام کاربران Workers AI در دسترس قرار خواهد گرفت. برای دریافت اطلاعرسانی در مورد در دسترس بودن این ویژگی، میتوانید در لیست انتظار ثبتنام کنید.
نتیجهگیری
Cloudflare یکی از نخستین ارائهدهندگان امنیتی است که مجموعهای از ابزارها را برای ایمنسازی برنامههای مبتنی بر هوش مصنوعی عرضه کرده است. با استفاده از Firewall for AI، مشتریان میتوانند کنترل کنند که چه پرامپتها و درخواستهایی به مدلهای زبانی آنها میرسند و به این ترتیب، خطر سوءاستفاده و استخراج دادهها را کاهش دهند. ما شما را بهروز نگه میداریم و به زودی اطلاعات بیشتری در مورد آخرین تحولات در زمینه امنیت برنامههای هوش مصنوعی منتشر خواهیم کرد.









ارسال دیدگاه
مجموع دیدگاهها : 0در انتظار بررسی : 0انتشار یافته : ۰